02. Transport Layer
01에서는 application layer를 배워보았다. 생각해 보면 사용자와 밀접하게 연관되어 있어 최종 결재자 느낌이다. 또한 application layer에 여러개의 프로세스가 socket이라는 문과 함께 떠있고 port 번호를 통해 구분이 된다고 했다. 그렇다면 자연스럽게 transport layer의 역할 중 하나가 port번호에 맞는 socket을 찾게 도와주는 역할! 오오오 드디어 연결 되었다. 그래서 이번 글은 방금 같은 분류 역할과 UDP와 TCP, TCP의 부가 기능들, 데이터 송수신 규약들을 이야기 해보겠다. 레고~ 앗 참고로 4계층에서는 선물포장지를 segment라 하기로 한 점 잘 기억하기 바란다.
1. UDP와 TCP의 비교
사실 저번 글 부터 근근히 많은 예시를 들었다. 그래서 이젠 좀 깊게 다뤄서 완전히 끝내보자.. 근데 사실 다룰거 별거 없다.
TCP의 경우 사전에 3-way handshaling을 하여 두 호스트간의 연결을 중시한다. 이 과정을 말하자면, client가 server에게 "너 나랑 대화 좀 해(SYN)"을 보낸다. 그럼 클라이언트가 "그래, 안그래도 너랑 할 말 많았어(SYN+ACK)"을 보내면 client가 "옥상으로 따라와(ACK)" 이렇게 세번의 메시지 주고 받기가 일어난다. 그 담에 옥상에서 실컷 치고박고 하면(데이터 주고받기) 이제 선생님에게 혼나지 않게 늦지 않게 수업에 들어가기 위해 3번의 통신이 또 일어난다. client가 먼저 "후 이제 그만 하자(SYN)"을 보내면 server가 "흠,, 그럴까.. 음,,,(ACK)"을 보내고 잠깐의 고민 후에 "ok 들가자(SYN)"을 보내면 client가 "그래 쉅 늦지 말고(ACK)" 이후에 두 host간의 연결은 끊기게 된다. 이처럼 3-way handshaking을 하고 데이터를 주고 받고 연결을 끊을 때 조차도 최대한 동시에 끝내기도 하고 일단 연결을 한다는 것에서 부터 상당히 데이터를 안정적으로 주고 받을 수 있다는 것이다(그래서 byte stream이라는 이름까지 붙여져 있다). 또한 두 호스트만 있기에 데이터가 순차적으로 움직일 수 있다. 더욱이, 데이터가 손실이 일어났는지도 쉽게 확인 가능하고 쌍방으로 데이터를 보내고 받을 수도 있다. 마지막으로 중요한 기능은 fast retransmit라고 수신자가 순서에 맞게 안 온 패킷에 대해 이전에 보냈던 수신 메시지(ACK)를 세 번 보낸다. 그러니깐 예를 들면 100번 받고 120번 받아야 하는데 120안왔으면 100ACK 을 세 번이나 파파팍 보낸다는 뜻이다. 이를 3 duplicate acks 이라 부른다.
UDP의 경우 사전 연결 없이 눈 감고 보내버린다. network를 구성하는 라우터들은 딱 필요한 만큼만의 정보들을 통해서 목적지에 보낸다. 그래서 상당히 빠르지만 데이터 손실이 일어났지만 모르는 경우가 허다하고 보낸 녀석의 순서대로 데이터가 도착하지 않기에 정리하는 과정이 필요하다.
그러하니 잘 생각해보면 파일 같은 것을 전송할 때는 비교적 느리지만 모든 정보가 확실하게 올 수 있는 TCP가 좋은 것이고 실시간 스트리밍을 볼 때는 중간에 약간은 끊겨도 좋으니깐 빠르게 데이터가 받아지고 server입장에서도 하나하나 연결할 시간을 제하고 그냥 마구잡이로 보내기 좋은 UDP를 사용한다.
2. Multiplexing& Demultiplexing
위에서 말한 port에 맞는 socket 찾아주는 역할! Multiplexing은 mux로 Demultiplexing은 demux라고 부르겠다. 옆에 그림처럼 Server에서 여러 클라이언트에게 동시에 연결되어 두 프로세스가 생겼고 그에 맞는 socket이 각각 연결된 상황이다. Server의 P1과 P2에서 정보가 나갈때 mux가 되어 밑에 계층인 network layer에 내려간
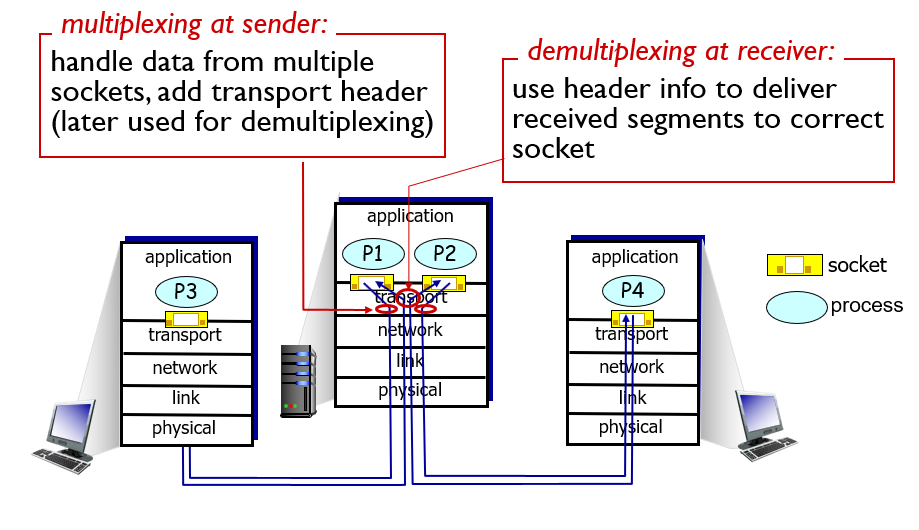
다. P3과 P4에서 들어온 정보를 각각 맞게 P1과 P2의 socket에 넣기 위해 demux를 하는 것이다. 작아서 잘 안보일 수 있는데 가운데 큰 동그라미가 demux고 작은 동그라미 끼리 mux하는 거다. 다중화, 역다중화 뭐 이런 느낌.
mux는 뭐 사실 아래로 내려가면서 함께 포장되다가 각 목적지 맞게 보내질 거 같으니 그렇다 쳐도 demux는 꽤 궁금점들을 남긴다. 어떻게 저렇게 잘 돼?
TCP/UDP 세그먼트에는 목적지와 출발지의 port 번호가 명시되어 있다. 이 port번호와 IP주소를 통해 각각에게 맞는 socket들을 찾아준다. IP주소는 어디에 명시되어있느냐! network layer에서 받을 때 이미 해석이 되어 버렸다.
2-1. UDP와 TCP의 demux
먼저 UDP의 경우, 세그먼트에 명시되어 있는 목적지의 port 번호가 같은 두 개의 다른 IP 주소에서 쏘아 올린 세그먼트는 같은 socket에 들어간다. 이것을 다른 말로는 connectionless demux라고도 부른다. 아래 그림 중 왼쪽의 것을 보면 P3과 P4는 다른 host임에도 불구하고 같은 P1의 socket을 사용한다.
반면 connection-oriented demux인 TCP의 demux인 경우 진짜 별거 별거 다 신경 쓴다. dest의 IP와 port 뿐만 아니라 source의 IP& port에 따라 socket이 나뉜다. 정말 예민한 친구야.. 하지만 그만큼 안정적이겠지?! 아래 그림의 오른쪽의 것을 보면 P1과 P2, P3의 dest port번호가 전부 다 같지만 각기 다른 socket에 들어간다. P2와 P3의 IP는 같음에도 불구하고(한 컴퓨터니 당연..) source 의 port번호가 달라 서로 다른 socket에 들어간다! 신기방기


3. 안정적으로 데이터를 주고 받기 위한 수많은 약속들
- rdt : application layer입장에서는 밑에서 오는 정보들은 모두 다 신뢰할수 있다고 생각한다. 여기서 신뢰란 받는 사람 입장에선 현재 이 데이터가 넘어오는게 맞고 보내는 사람 입장에서는 이 데이터가 잘 갔으리라 믿는 것이다. 이런 신뢰할 수 있게 데이터를 주고 받기 위해 수많은 절차들을 만들어 왔지만 최종적으로 채택된 3.0버전을 간략하게 소개한다.
rdt3.0의 주요 개념은 송신자가 0번 인덱스인 data를 보내고(인덱스를 0과 1을 번갈아 새긴다) timer를 설정한다. timer가 도는 사이에 수신자에게 수신확인 표시(ACK)이 오지 않거나 1번 인덱스 데이터를 받았다는 수신확인표시가 오면 timeout이 되게 유도한 후에 다시 보내고 timer를 재 설정 한다. 그 후에 1번 인덱스를 새긴 data를 보내고 과정을 반복한다.
수신자 입장에선 0번 데이터 받을 순서에 0번 받으면 잘 받았습니다~ 하면 되는데 1번 받았으면 1번 받았다고 하면 알아서 다시 보내주니 좋다.
하지만 만약에 1번 수신 확인 메시지를 보냈는데 너무 오래걸려서 송신자 입장에서 timeout이 일어나 1번 패킷을 다시 보내버리고 나자 좀 이따가 1번 수신 확인 메시지를 받아버리게 되면 송신자는 세상 잘 된다고 생각하게 된다. 이 순간부터 이제 꼬이는데 결과적으로는 수신자는 하나의 packet을 두번 씩 받게 된다. ㅜㅜ
- pipelined protocol : rdt를 보면 각각 하나의 packet을 보내게 되는데 송신자 입장에서는 하나 보내고 수신 확인 메시지가 올 때까지 기다린다... 이 기다리는 시간이 길다면? 너무나도 비효율적,, 그래서 한번 보낼 때 여러개를 보내기로 한다...!!! 이를 pipelined protocol이라 부르고 크게 두가지로 나뉜다 GBN과 Selective Repeat. 이 둘은 간단하게 개념적으로만 이야기 하자.
GBN(go back N)은 송신자가 여러 개 packet을 때려 넣은 후에 받은 쪽이 수신 확인 문자(ACK)을 받을 때 까지 기다리는데 만약에 5개 보냈는데 3번 ACK이 안왔으면 3번부터 그 뒤에거 까지 다 보낸다.
Selective Repeat은 GBN과 다르게 3번 ACK이 안왔으면 3번만 다시 보낸다.
4. TCP의 부가기능인 flow control과 congestion control!
이번 문단을 끝으로 transport-layer에 대한 이야기가 끝난다.. 휴 생각보다 힘들지만 프랑스 왕자로서 끝까지 밀고 나가겠다. 일단 두 용어의 개념을 이야기 하자면, flow control은 흐름 제어로서 수신자가 받아 들일 수 있는 전송 속도보다 송신자가 더 밀어 넣으면 안된다는 것이다. congestion control은 혼잡제어로서 송수신자 간이 아닌 이들을 연결해주는 network core(인터넷 망)에 너무 많은 데이터를 실어 보내버리면 core에서 과부화가 걸려 버릴 수 있으니 이를 조절한다는 개념이다. 그럼 이 두 개를 어떻게 할까?
flow control의 경우 수신자가 rwnd라고 자신이 얼만큼의 여유공간이 있는지 TCP header에 명시해 준다. 보내는 사람은 이것을 참고해 아 이정도 보내면 괜찮겠구나~ 하고 보내는 것이다.
congestion control은 컨셉이 AIMD라는 것인데 증가는 찔끔 씩 하고 내려갈 땐 팍팍 내려가는 걸 말한다. (마치 내 주식 상황 같군,,) rwnd와 비슷하게 여기서는 cwnd가 있고 그냥 컴퓨터가 예측하는 것이다. 누가 알려주는게 아니다. cwnd는 rwnd처럼 마찬가지로 core에 얼마만큼의 속도를 감당 가능한지의 개념이다. 기준 초인 RTT가 1씩 증가할 때마다 cwnd가 1씩 증가하다가 core에서 충돌이 일어나버리면(time out or 3 dup ack) cwnd를 현재 값의 반 값으로 설정한다.
근데 이제 증가를 1씩만큼 하니깐 사람들이 답답했는지 TCP Slow Start라는 개념이 나오고 이 개념을 이용한 다른 두 버전의 congestion control이 등장한다 TCP Reno와 TCP Tahoe가 그것이다.
TCP slow start는 그냥 1씩만큼 증가했던 cwnd의 크기를 두 배씩 증가 시킨다는 것이다.
TCP Tahoe는 송신자 입장에서 cwnd가 100인 상태에서 timeout이나건 3dup acks 를 받건 cwnd를 1로 만들고 cwnd가 이전 값 100의 절반인 50까지는 slow start를 하다가 50이 되면 1씩 증가한다.
TCP Reno의 경우 timeout일 경우 Tahoe처럼 일을 처리하지만 3 dup acks을 받으면 50에서 부터 1씩 증가한다.
5. 마무리..
이렇게 4계층 까지 끝났다. 생략한 부분이 꽤 있는데 사실 이정도만 알아도 꽤 자세한 흐름은 아는 것이라 생각하고 만족한다.. 이제 3계층과 2계층을 다루게 되겠지? 1계층인 physical layer는 다룰 것이 없어서 안할거야~~ 아무튼 3계층 2계층은 좀 쉬었다가 저번 약속처럼 알고리즘 글들 좀 올리고 마저 올려야 겠다. 사실 알고리즘 공부를 제일 좋아하고 많이 하는데 하나 밖에 안올려서 좀 그르네~ 암튼 내 알고 글들 기대하셔~ :)