[OS] Memory management
0. 기본 개념
프로세스가 돌아가기 위해서는 cpu와 메모리가 필요하다. 프로세스가 돌아가기 위해 필요한 메모리를 할당하는 방식은 크게 두가지가 있다. 정적할당 - 실행 이전에 전역변수, static 변수를 메모리에 올린다. 동적할당 - 실행 시점에 동적으로 필요한 만큼만 할당한다.
또한 메인 메모리는 크게 두 가지 영역으로 나뉜다. kernel 영역과 user 영역. 뿐만 아니라 multi programing이 생겨남에 따라 user 영역에 한번에 여러 어플리케이션이 올라가기도 한다. 그에 따라 서로 서로 침범하지 않게 잘 나누어야 한다.
1. 메모리 관리의 역할
메모리 관리라는 것은 어떠한 것들을 제공해 주는 것일까? 하나씩 살펴보자
- Relocation: 많은 프로세스는 하나의 메인 메모리에 다함께 올라간다. 우리는 이때 어떤 프로세스가 어떤 부분에 배치될지 알 수 없다. 뿐만 아니라 메모리 용량이 부족하다면 disk로 빠져나갈 수도 있다. 그렇게 빠져나간 프로세스는 다시 메모리에 올라오지만 이때 기존의 위치랑 달라질 수 있다.
- Protection: 각 프로세스는 다른 프로세스에 의해 자신의 메모리 영역이 침범당해서는 안된다. 따라서 모든 메모리 접근 연산은 해당 프로세스가 할당 받은 고유 영역인지 항상 확인해야 한다. 만약 침범 한다면 실행을 중지 시켜야겠지?!
- Sharing: protectoin과 상반되는 개념이다. 라이브러리, kernel code 처럼 굳이 여러 군데에서 사용 되는 경우 각 프로세스마다 메모리를 계속 할당할 필요가 없다. 이럴 경우는 공유해서 접근 가능하게 하는게 더 좋지 않을까?!
- Logical Organization: 프로세스에서 사용하는 주소와 실제 메모리 상의 주소는 다르다. 논리적으로는 아래 그림 처럼 구조화 되어 있다고 생각한다.
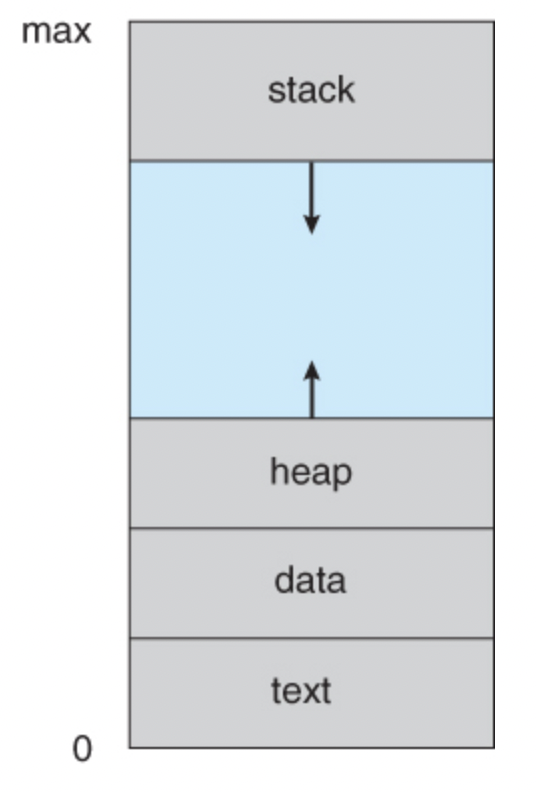
하지만 왼쪽과 같이 할당해 버리면 stack과 heap 사이의 영역은 굉장한 낭비가 발생한다. 이를 방지하기 위해 실제 메모리에는 segmentation을 적용한다. 즉, stack - heap - data - text 영역 4가지 묶음으로만 메모리 상에 저장한다. 그에 따른 부수적인 것(분산적재)은 밑에서 확인하고, 중요한 것은 프로세스는 왼쪽(논리 주소)과 같이 할당 되어 있다고 생각한다. 그렇기 때문에 중간에 어떤 녀석(MMU)이 논리 주소를 물리 주소로 바꾸어주는 역할을 해야 한다.
- Physical Organization: virtual memory에 관한 이야기인데, 컴퓨터 메모리는 최소 2계층으로 이루어져 있다. main memory와 disk. 어떤 굉장한 프로그램이 있다고 가정하자. 이 프로그램은 일주일에 한번식 out이라는 기능을 해야하는데 out 기능을 하려면 500MB가 필요하다고 하자. 굉장하다.. 일주일에 한 번 호출하기 위해 항상 500MB를 메모리에 올릴 수는 없다. 이런 경우를 방지하기 위해 disk에 있는 내용을 전부 메모리에 올리는 것이 아닌 필요한 부분만 memory에 올리고자 하는 것이다. 즉 부분 적재 기능이 필요하다.
2. 주소 체계
주소에는 3가지 type이 존재한다.
- Symbolic address: source 코드 상에서 사용되는 주소를 의미한다. 변수 이름, 상수, 함수 이름(label) 등 코드 돌아가면서 사용되는 상징들 주소를 의미한다. int x = 10; 에서 x를 의미한다.
- Logical address(relative address, virtual address): x의 주소를 의미한다. 프로세스가 작동하면서 필요한 메모리 주소들. 컴파일 시점에 상징 주소에서 논리 주소로 변환된다. 모든 프로세스에서 논리 주소의 시작점은 0 부터 이다.
- Physical address: 메인 메모리 상에서 실제 논리 주소의 위치를 말한다. 메모리 상에서 정말 x가 저장되어 있는 위치. loader가 메인메모리에 프로세스가 올라갈때 위치를 정해준다.
프로세스 입장에서는 항상 나의 메모리는 0에서부터 시작한다. 프로세스 상에서 예를 들어 8byte 씩 10번 째로 할당 받은 데이터 영역의 어떤 값은 메모리 상에서 80에 위치해야만 한다. 하지만 메모리 상에서는 해당 프로세스의 데이터 영역 시작 위치를 pointer로 PCB에서 관리하고 있어 해당 값 + 80에 그 데이터가 저장되어 있다. 이처럼 논리 주소를 물리주소로 변환해주는 녀석을 MMU라고 한다. 이렇게 transparent(있는데 없는 것 처럼) 하는 이유는 컴파일러가 메모리를 변환하는데 간편하기도 하고 다른 영역의 메모리에 대한 정보를 알 수 없도록 하는 역할을 하기도 한다.
3. 메모리 할당 방식
굉장히 다양하다.
연속 할당 - 고정 할당
- 일정한 크기
- 일정하지 않은 크기
- 동적 할당
- buddy system
불연속 할당 - paging
- segmentation
위와 같이 구분된다. 하나씩 알아보자
3.1 Fixed partitioning

- equal-size partition (균등 고정 분할 방식)
오른쪽 그림과 같이 모든 메모리 영역을 4MB로 나누는 것이다. 각 프로세스당 한칸씩만 접근 할 수 있다.
딱 봐도 여러 문제가 보인다. (1) 4MB보다 큰 process는 서비스 불가. (2) 최대 4개 까지만 동시에 올라갈 수 있음. (3) 버려지는 부분들 (1MB씩 총 4MB)가 존재함. 이를 내부 단편화(internal fragment)라고 한다.
물론 장점들도 존재한다. 구현하기 쉽고 어디에 올릴 지 판단하기 쉽다는 것. 그리고 소형 embedded system 처럼 한번에 적은 프로세스의 수와 전반적으로 3MB 정도만 필요하다고 하면 굉장히 효율 적인 메모리 할당 방식이 될 것이다.

- unequal-size partition (비균등 고정 분할 방식)
왼쪽 그림과 같이 메모리 크기를 다양하게 분할한다. 4/8/8/16 처럼. 총 36MB임을 알 수 있다. 만약 모든 프로세스의 크기가 10MB 라면 차라리 12씩 3칸으로 나눈게 더 이득일 수 있다.
이 경우도 당연히 내부단편화 가 존재할 수밖에 없다.
3.2 Dynamic partitioning
정적분할의 단점을 넘어서기 위해 동적 분할 방식이 등장했다. 프로세스가 요청하는 메모리 만큼 할당해 주는 방식이다.

위 그림처럼 요청한 만큼만 쌓아주다가 P2,P4 처럼 빠지게 되면 해당 부분에 올릴 수 있는 프로세스를 올린다. 이 또한 단점이 존재하는데 P2가 빠지고 P6이 들어가면서 2MB 정도의 빈 공간이 생겼다. 이런 구멍을 Externel fragment(외부 단편) 이라고 한다. 외부 단편들을 없애는 방식 중 compaction이라는 처리를 진행한다. 즉, 빈 구멍을 없애기 위해 쫙 뭉쳐놓겠다 이건데 이런 작업은 cpu의 처리를 요구하기에 trade off가 존재한다.
이때 어떻게 빈 구멍에 프로세스를 올릴까?
- First-fit: 위에서 부터 탐색하면서 처음 등장하는 빈 영역에 넣는다
- Next-fit: 마지막으로 삽입한 위치 부터 탐색을 시작한다.
- Best-fit: 요구하는 메모리 크기와 가장 비슷한 곳에 넣는다.
first와 next는 O(1)에 실행 되지만 Best-fit은 O(n) 만큼 탐색 시간이 걸린다. 뿐만 아니라 더 작은 Externel fragment를 계속해서 생성해 나간다. 그렇다. best-fit은 이름만 best-fit이지 최악이다..
3.3 buddy system
동적 분할과 정적 분할을 같이 하는 것이다. 아래 사진처럼 총 128kb가 존재한다고 하자. 만약 10 kb 정도의 메모리를 요구한다면 16kb 가 될 때까지 반씩 조깨어 최대한 덜 할당한다.

만약 어떤 프로세스가 나가게 되면, 해당 크기의 반대편 쌍의 메모리 영역을 보아서 아무것도 없으면 두 영역을 coalesces, 합친다. 물론 이 경우도 내부 단편은 생긴다. 하지만 상당히 줄어드니 이득!
3.4 Paging (분산적재)
이제 생각을 조금 바꾸어 보자. 꼭 연속되게끔 메모리를 할당해야 할까? 뭉텅이로 하려다 보니 위와 같은 문제들이 생겨났다. 차라리 부분부분 올리면 훨씬 낫다. 예를 들어 A(4칸), B(3칸), C(4칸) 과 같이 메모리에 순서대로 차곡차곡 있다가 B가 나가고 D(5칸)이 들어오면 C 밑에 넣는 것이 아닌 B가 나간 자리에 3칸 넣고 C밑에 2칸을 넣는 것이다.
이때 칸을 page라고 부른다. 대신 이젠 구현의 복잡도가 생겼다. 하나의 프로세스가 page 단위로 분할되어 여러 군데에 분산 적재 되다 보니 page별 메모리 상 위치를 가지고 있어야 한다. 또한 MMU의 역할이 더욱 복잡해 졌다.
주소 변환에 대해 다루어 보자면, page의 크기를 2의 n제곱수 만큼으로 잡아 놓는다. 즉, 그렇다면 메모리 주소를 2진수로 표현하니 그 중 상위 n bit가 page의 번호라고 할 수 있다. 그렇다면 page 번호와 해당 page의 시작 주소를 담고 있는 page table을 참고하여 물리 주소로 변환하기 굉장히 쉽다. 뿐만 아니라 page의 크기를 알고 있으니 변환된 주소가 page의 크기를 넘어가면! 삐빅 하면 된다.
paging의 장점으로는 마지막 page를 저장하고 있는 칸에만 내부 단편이 생긴다는 것과 외부 단편이 없다는 장점이 있다.
3.5 Segmentation(분산 적재)
이 분산 적재는 논리적 가변길이로 조각내자는 것이다. process를 부분 별로 나누는 것이다. stack, data, code, libraray 등등 성격이 비슷한 segment로 나누어 성격에 맞는 속성들을 부여해서 관리한다. 이 경우도 paging과 마찬가지로 segment 별로 limit와 bound를 정해 할당된 메모리 영역을 관리한다. page table과 비슷하게 각 segment 별로 index를 두어 이 index로 segment table을 유지하여 주소 변환을 한다. 뿐만 아니라 segment별로 read/write/excute 권한을 주거나 공유 가능하게 하는 등 다양한 옵션을 줄 수 있다.
이 방식은 dynamic partitioning을 나누어서 진행 된 것이나 마찬가지이다. 그렇기에 외부 단편이 존재하고 compaction이 필요할 수 도 있다. 단지 동적 분할 방식 보다 외부 단편 크기가 더 작고 compaction도 많이 필요하지 않다는 것이다.